Architecture
This guide introduces Kubeflow ecosystem and explains how Kubeflow components fit in ML lifecycle.
Read the introduction guide to learn more about Kubeflow, standalone Kubeflow components and Kubeflow Platform.
Kubeflow Ecosystem
The following diagram gives an overview of the Kubeflow Ecosystem and how it relates to the wider Kubernetes and AI/ML landscapes.

Kubeflow builds on Kubernetes as a system for deploying, scaling, and managing AI/ML infrastructure.
Introducing the ML Lifecycle
When you develop and deploy an AI application, the ML lifecycle typically consists of several stages. Developing an ML system is an iterative process. You need to evaluate the output of various stages of the ML lifecycle, and apply changes to the model and parameters when necessary to ensure the model keeps producing the results you need.
The following diagram shows the ML lifecycle stages in sequence:

Looking at the stages in more detail:
In the Data Preparation step you ingest raw data, perform feature engineering to extract ML features for the offline feature store, and prepare training data for model development. Usually, this step is associated with data processing tools such as Spark, Dask, Flink, or Ray.
In the Model Development step you choose an ML framework, develop your model architecture and explore the existing pre-trained models for fine-tuning like BERT or Llama.
In the Model Optimization step you can optimize your model hyperparameters and optimize your model with various AutoML algorithms such as neural architecture search and model compression. During model optimization you can store ML metadata in the Model Registry.
In the Model Training step you train or fine-tune your model on the large-scale compute environment. You should use a distributed training if single GPU can’t handle your model size. The results of the model training is the trained model artifact that you can store in the Model Registry.
In the Model Serving step you serve your model artifact for online or batch inference. Your model may perform predictive or generative AI tasks depending on the use-case. During the model serving step you may use an online feature store to extract features. You monitor the model performance, and feed the results into your previous steps in the ML lifecycle.
ML Lifecycle for Production and Development Phases
The ML lifecycle for AI applications may be conceptually split between development and production phases, this diagram explores which stages fit into each phase:

Kubeflow Components in the ML Lifecycle
The next diagram shows how Kubeflow components are used for each stage in the ML lifecycle:

See the following links for more information about each Kubeflow component:
Kubeflow Spark Operator can be used for data preparation and feature engineering step.
Kubeflow Notebooks can be used for model development and interactive data science to experiment with your ML workflows.
Kubeflow Katib can be used for model optimization and hyperparameter tuning using various AutoML algorithms.
Kubeflow Trainer can be used for large-scale distributed training or LLM fine-tuning.
Kubeflow Model Registry can be used to store ML metadata, model artifacts, and preparing models for production serving.
KServe can be used for online and batch inference in the model serving step.
Feast can be used as a feature store and to manage offline and online features.
Kubeflow Pipelines can be used to build, deploy, and manage each step in the ML lifecycle.
You can use most Kubeflow components as standalone tools and integrate them into your existing AI/ML Platform, or you can deploy the full Kubeflow Platform to get all Kubeflow components for an end-to-end ML lifecycle.
Kubeflow Interfaces
This section introduces the interfaces that you can use to interact with Kubeflow and to build and run your ML workflows on Kubeflow.
Kubeflow User Interface (UI)
The Kubeflow Central Dashboard looks like this:
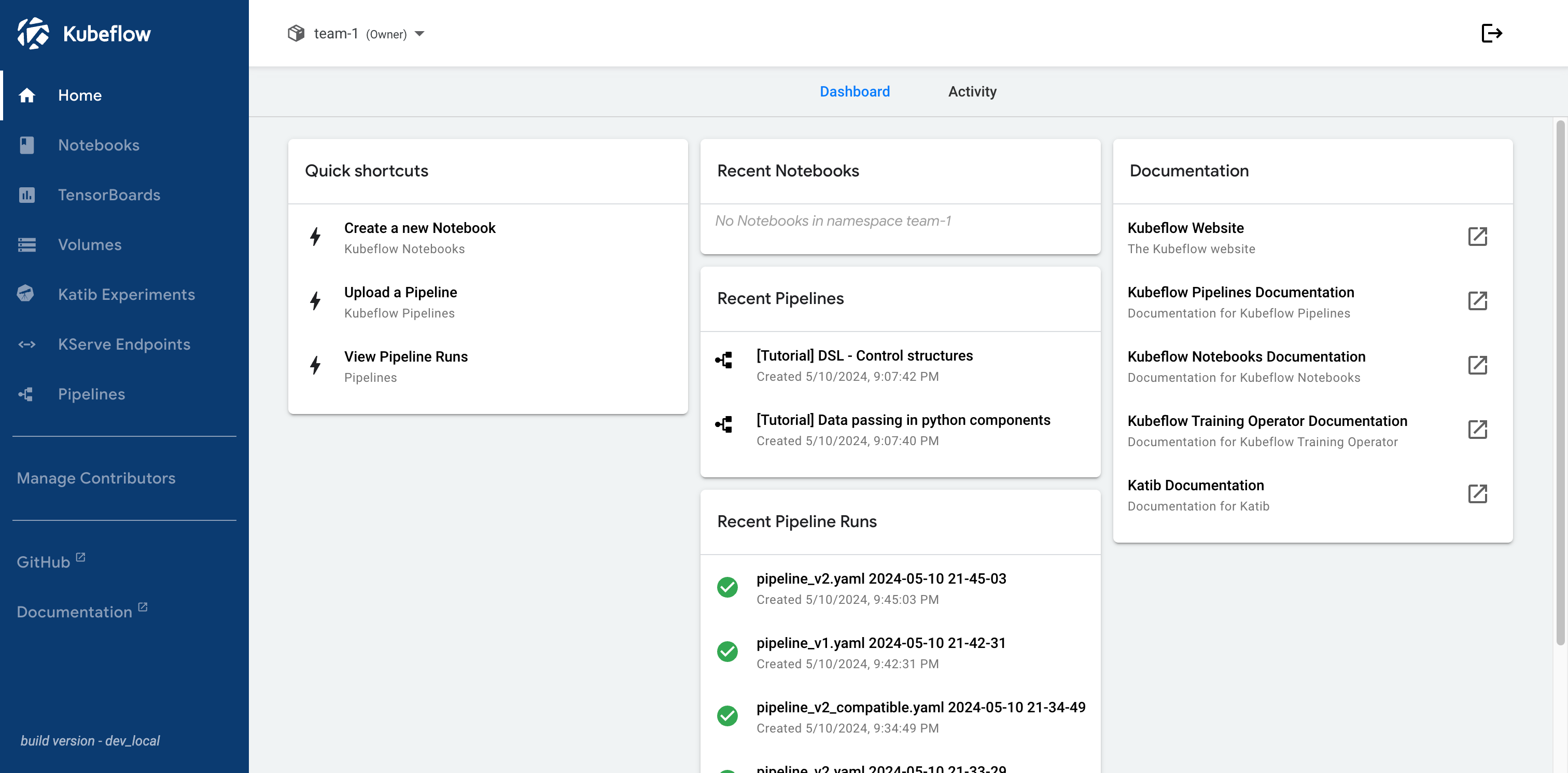
The Kubeflow Platform includes Kubeflow Central Dashboard which acts as a hub for your ML platform and tools by exposing the UIs of components running in the cluster.
Kubeflow APIs and SDKs
Various components of Kubeflow offer APIs and Python SDKs.
See the following sets of reference documentation:
- Pipelines reference docs for the Kubeflow Pipelines API and SDK, including the Kubeflow Pipelines domain-specific language (DSL).
- Kubeflow Python SDK to interact with Kubeflow Trainer APIs and to manage TrainJobs.
- Katib Python SDK to manage Katib hyperparameter tuning Experiments using Python APIs.
Next steps
- Follow Installing Kubeflow to set up your environment and install Kubeflow.
Feedback
Was this page helpful?
Thank you for your feedback!
We're sorry this page wasn't helpful. If you have a moment, please share your feedback so we can improve.